分類器 .. 應該是要講 氣死人的 "氣" 
上一篇提到我們會使用這三個監督式的分類演算法:
今天就直接用 Weka 先來做一次給大家看,怎麼從 Weka 上操作這三個分類演算法。
我們先採用 Iris (Anderson’s Iris data set) 這個資料集當作實驗。Iris 只要是玩過機器學習的人一定都測試過這個資料集,此資料集有 150 個範本和 4 個特徵,以及三個類別。
https://zh.wikipedia.org/wiki/安德森鸢尾花卉数据集
利用 Weka 讀入之後會得到此畫面
之後選則 Classify 的按鈕
然後選擇 Filter 內的 “Choose”,依據我們需要的三個分類演算法分別如下三個圖
Support Vector Machine
Naïve-Bayes
RandomForest
接著用這三個演算法測試一下執行 Iris 資料集分類的結果。這邊所有的參數以及 cross-validation 先都用預設的值,先不去做調整,因為 Iris 這筆資料我們只是先用來當作範例。等之後在測試我們的資料集時,這些參數再來做調整以達到最佳結果。
以 Naïve-Bayes 當範例,在右邊的 classifier output 會顯示初該分類器的分類結果:
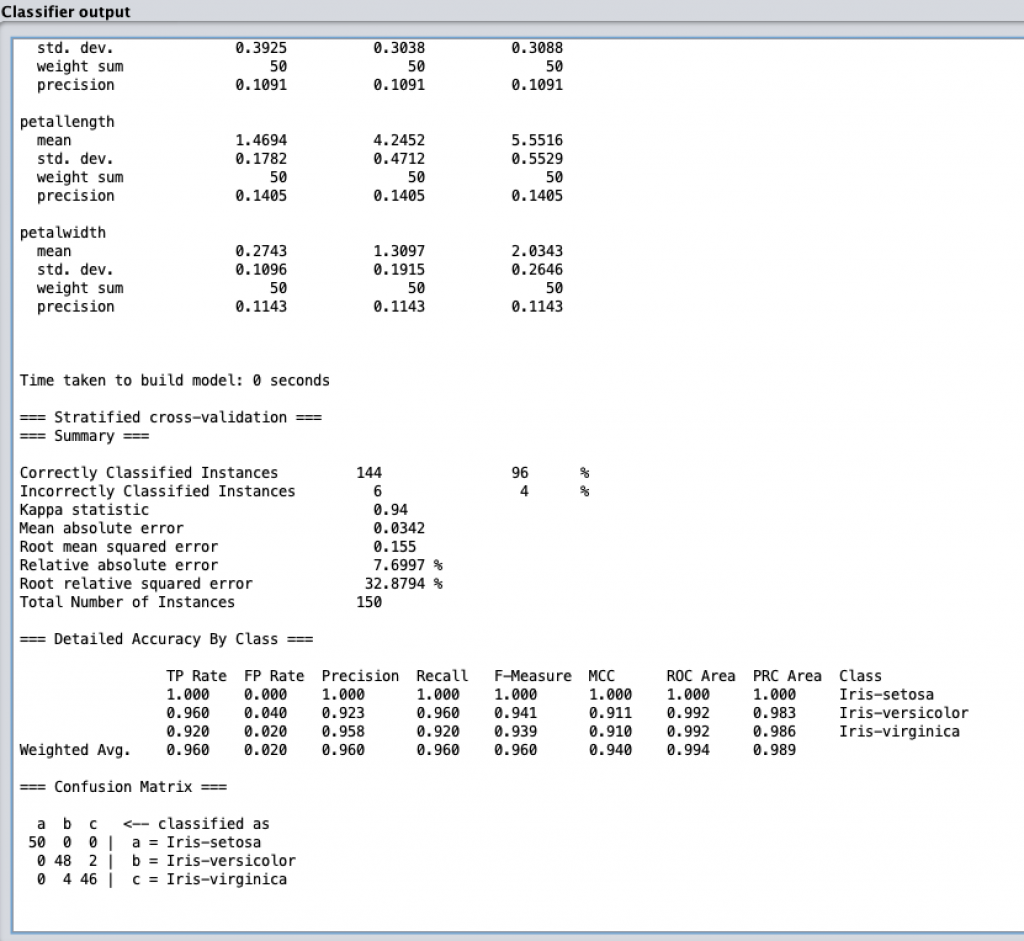
可以看到若用 Naïve-Bayes 當作分類器對 Iris 進行分類可以得到 96 % 的正確率 (accuracy)。而其他兩個分類氣的結果如下:
因為 Iris 的資料集的資料分布還算完整,所以目前常用的分類器結果都還算不錯。要注意的是,目前我們也還沒針對資料進行正規化 (Normalization),若這些資料再進行一些前處理的話,分類正確率也會提升。
好,這樣大家應該知道該怎麼操作 Weka 上的分類器了,之後我們在分類計算的部分都會直接使用 Weka 來操作。有關評估以及資料前處理等方式,就留待下一次的文章再來說明。
免責聲明:本文章提到的股市指數與說明皆為他人撰寫文章內容,包括:選股條件,買入條件,賣出條件和風險控制參數,只適用於文章內的解釋與說明,此提示及建議內容僅供參考之用,並不構成投資研究、認購、招攬或邀約任何人士投資任何投資產品或交易策略,亦不應視為投資建議。

